Action Recognition by Jointly using Shape,
Motion and Texture Features in Low Quality Videos
Saimunur Rahman, John See and Chiung Ching Ho
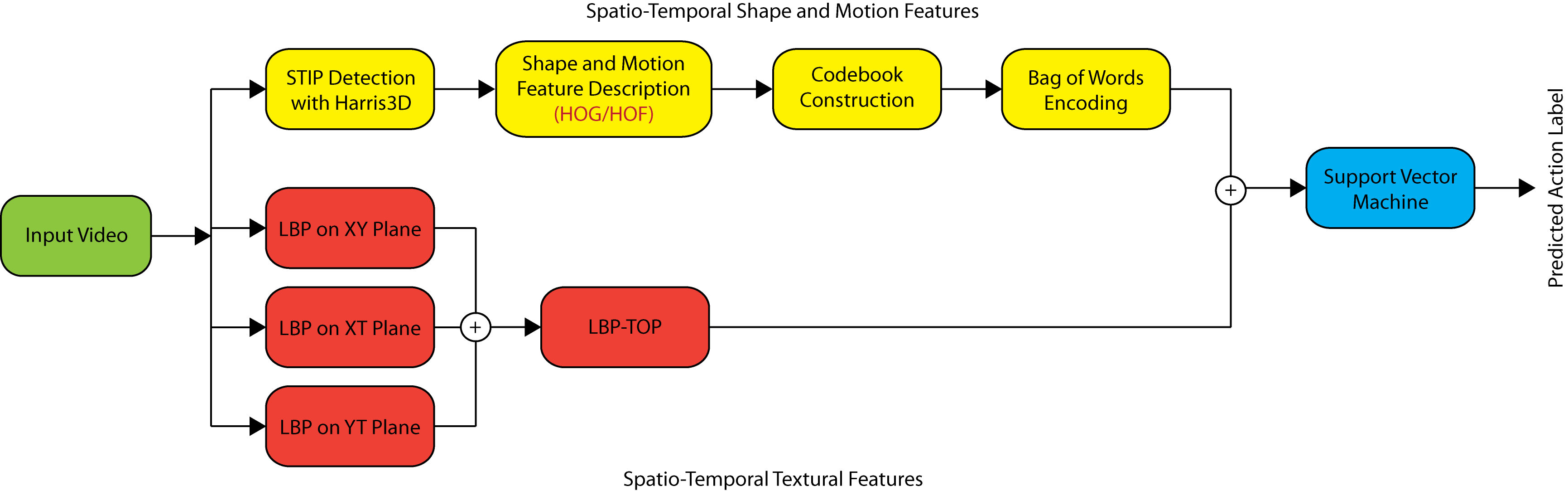
Figure: Joint Feature Utilization (JFU) Framework for Action Recognition in Low Quality Videos
Abstract
Shape, motion and texture features have recently gained much popularity in their use for human action recognition. While many of these descriptors have been shown to work well against challenging variations such as appearance, pose and illumination, the problem of low video quality is relatively unexplored. In this paper, we propose a new idea of jointly employing these three features within a standard bag-of-features framework to recognize actions in low quality videos. The performance of these features were extensively evaluated and analyzed under three spatial downsampling and three temporal downsampling modes. Experiments conducted on the KTH and Weizmann datasets with several combination of features and settings showed the importance of all three features (HOG, HOF, LBP-TOP), and how low quality videos can benefit from the robustness of textural features.
Method
We propose a joint utilization of shape, motion and texture features for robust recognition of human actions in low quality downsampled videos. The short description of used features are given below:
- Shape and motion: For each given sample point (x,y,t,\sigma,\tau), a feature descriptor is computed for a 3-D video patch centered at (x,y,t) at spatial and temporal scales \sigma,\tau. In this work, we employ the Harris3D detector (a space-time extension of the popular Harris detector) to obtain spatio-temporal interest points (STIP) (Laptev and Linderberg'2003). Briefly, a spatiotemporal second-moment matrix is computed at each video point \mu(.,\sigma,\tau)=g(.,s\sigma,s\tau)*(\nabla L(.,s\sigma,s\tau)L(.,s\sigma,s\tau)^T) using a separable Gaussian smoothing function g, and space time gradients \nabla L. The final location of the detected STIPs are given by local maxima of H = det(\mu) - k \textnormal{trace}^3(\mu). We used the original implementation available online and standard parameter settings i.e. k = 0:00005, \sigma^2= \{4; 8; 16; 32; 64; 128\} and \tau^2={2,4} for original videos and a majority of downsampled videos. To characterize the shape and motion information accumulated in space-time neighborhoods of the detected STIPs, we applied Histogram of Gradient (HOG) and Histogram of Optical Flow (HOF) descriptors as proposed by Laptev et al. (2008). The combination of HOG/HOF descriptors with interest point detectors produces descriptors of size n_x(\sigma) = n_y(\sigma)=18, n_t(\tau)=8 Each volume is subdivided into a n_x\times n_y\times n_t grid of cells; for each cell, 4-bin histograms of gradient orientations (HOG) and 5-bin histograms of optical flow (HOF) are computed. In this experiment we opted for grid parameters n_x,n_y=3, n_t=2 for all videos, as suggested by the Laptev et al. (2008).
- Textures: One of the most widely-used texture descriptor, Local Binary Pattern (LBP) produces a binary code at each pixel location by thresholding pixels within a circular neighborhood region by its center pixel (Ojala and Pietikäinen, 2002). The LBP_{P,R} operator produces 2^P different output values, corresponding to the 2^P different binary patterns that can be formed by the P pixels in the neighborhood set. After computing these LBP patterns for the whole image, an occurrence histogram is constructed to provide a statistical description of the distribution of local textural patterns in the image. This descriptor has been proved to be successful in face recognition (Zhao et al. 2007). In order to be applicable in the context of dynamic textures such as facial expressions, Zhao et al. (2007) proposed LBP on Three Orthogonal Planes (LBP-TOP), where LBP is performed on the three orthogonal planes (XY, XT, YT) in the video volume by concatenating their respective occurrence histograms into a single histogram. LBP-TOP is formally expressed by LBP-TOP_{P_{XY},P_{XT},P_{YT},R_X,R_Y,R_Z} where the subscripts denote a neighborhood of P points equally sampled on a circle of radius R on XY, XT and YT planes respectively. The resulting feature vector is 3.2P in length. The LBP-TOP encodes the appearance and motion along three directions, incorporating spatial information in XY-LBP and spatial temporal co-occurrence statistics in XT-LBP and YT-LBP. In this experiment we apply the parameter settings of LBP-TOP_{8,8,8,2,2,2} with non-uniform patterns as specified by Mattivi and Shao (2009), which produces a feature vector length of 768.
Spatial and Temporal Downsampling
In this work, we investigate the performance of action recognition with low quality videos that have been downsampled spatially or temporally, proposing suitable features that are robust. For now, we first describe the spatial and temporal downsampling modes that were employed in this work.
- Spatial Downsampling (SD):
Spatial downsampling produces an output video with a
smaller resolution than the original video. In the process,
no additional data compression is applied while the frame
rates remained the same. For clarity, we define a spatial
downsampling factor, \alpha which indicates the factor in which
the original spatial resolution is reduced. In this work, we
fixed \alpha= \{2, 3, 4\} for modes SD_\alpha, denoting that the
original videos are to be downsampled to half, a third
and a fourth of its original resolution respectively. Fig. 1
shows a sample video frame that undergoes SD_2, SD_3
and SD_4. We opted not to go beyond \alpha = 4 as extracted
features are too few and sparse to provide any meaningful
representation.

Figure 1: Spatial Downsampling of Video Frames (Rescaled to original size for view purpose).
- Temporal Downsampling (TD): Temporal downsampling produces an output video with smaller temporal sampling rate (or frame rate) than the original video.
In the process, the video frame resolution remained the same. Likewise, we also define a temporal downsampling factor, \beta which indicates the factor in which the original frame rate is reduced.
It has been seen that high temporal resolution; with high
spatial resolution produces high dynamic range i.e. high
motion information. It is based on the assumption that nonconstant
intervals would yield jerky motion, i.e. perceivable
discontinuity in the optical flow field. This assumption is
true for the majority of video sequences, which contain
motion, captured at the frame rate of 30 or less. Low quality
videos usually have this kind of motion discontinuity.
In this work, we use values of \beta = \{2, 3, 4\} for
modes TD_\beta, denoting that the original videos are to be
downsampled to half, a third and a fourth of its original
frame rate respectively. In the case of videos with slow
frame rates or short video lengths (such as in the Weizmann
dataset (Blank et al. (2005))), \beta may only take on smaller range of values
to extract sufficient features for representation.

Figure 2: Temporal Downsampling of Video Frames (Only black colored video frames are considered).
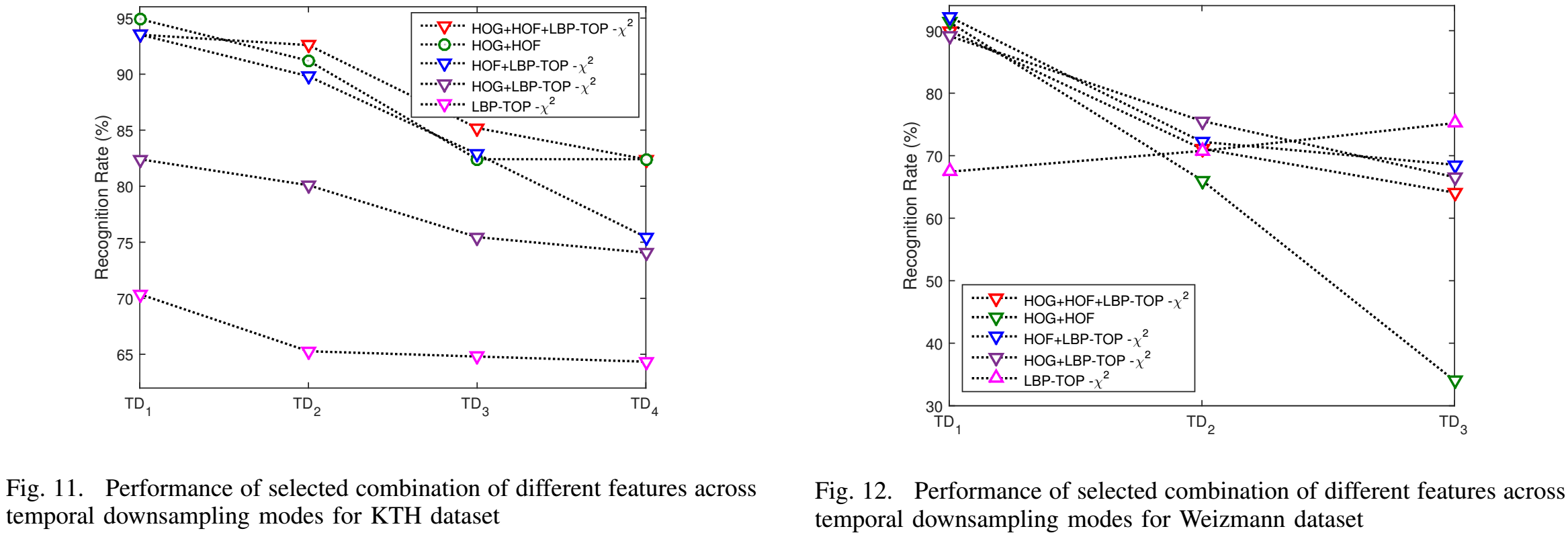
Results
- Results on Original Datasets
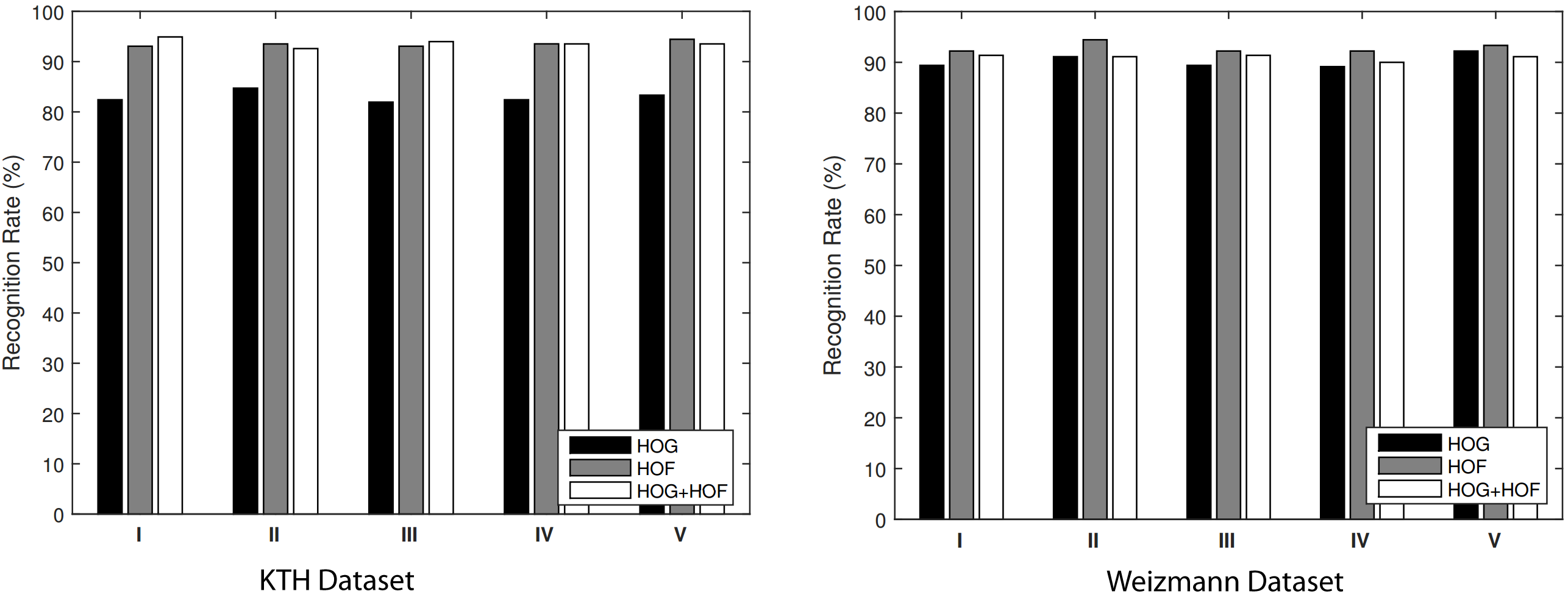
Recognition rate of different combination of features on original KTH and Weizmann dataset videos
- Results on Original Datasets
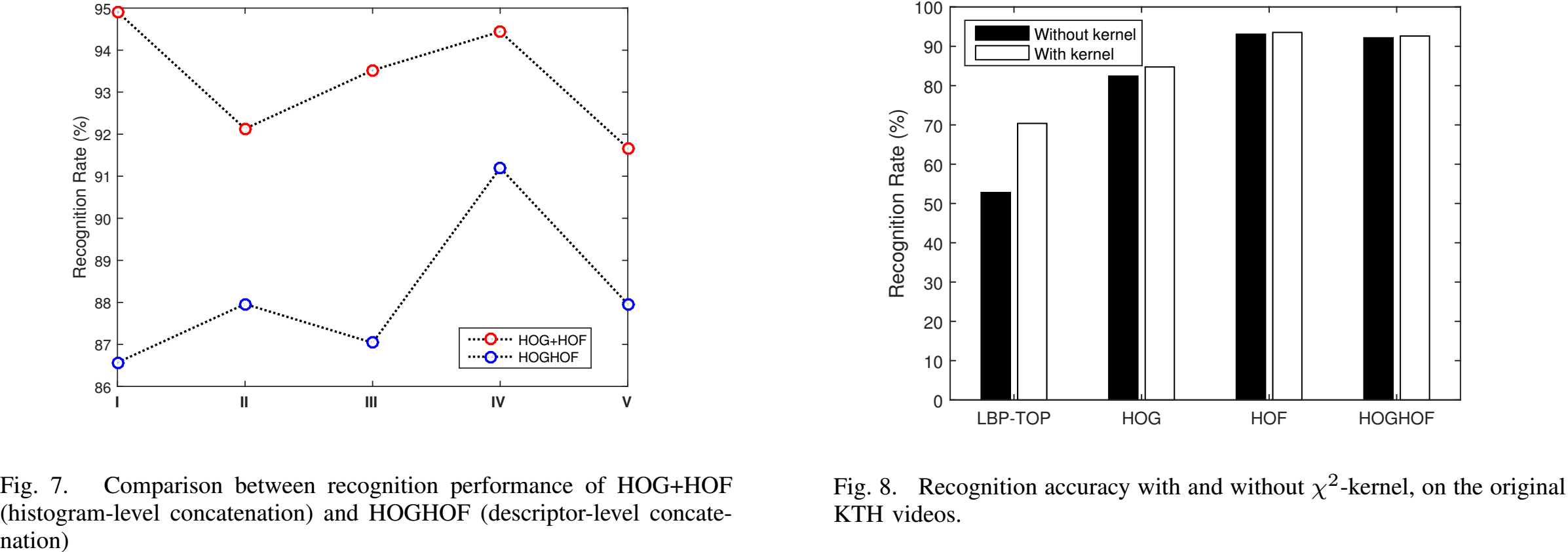
- Results on Spatially Downsampled Videos
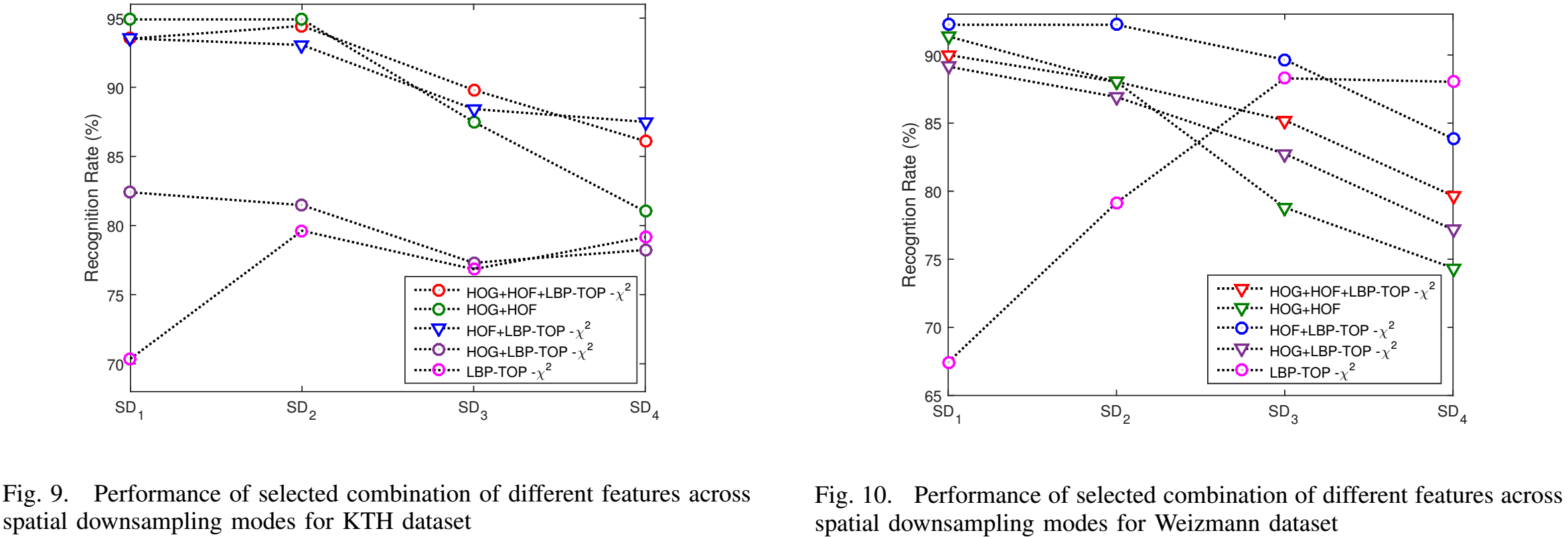
- Results on Temporally Downsampled Videos
Downloads
Downsampled datasets, extracted descriptor files and codes will be coming soon.
Reference
Saimunur Rahman, John See and Chiung Ching Ho, “Action recognition by jointly using shape, motion and texture features in low quality videos”, in IEEE International Conference on Signal and Image Processing Applications (IEEE ICSIPA 2015), Kuala Lumpur, Malaysia, Oct. 2015, pp. 83-88.